
iText is an OCR tool which could recognize text from any image.
You can use iText to extract text from PDF, document in paper, page in a book and any other images.
1. Easily Select Image
iText supports a variety of ways to select images, the operation is very convenient.
1.1 Capture Screen
iText has built-in screen capture tool. Just press the shortcut ⇧⌘1, capture any area on the screen, you can extract the text in it.
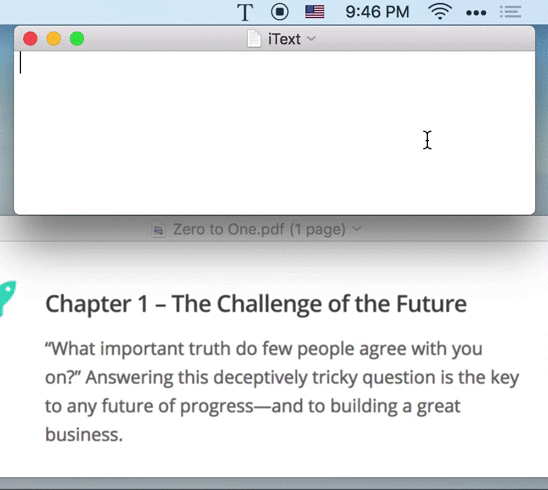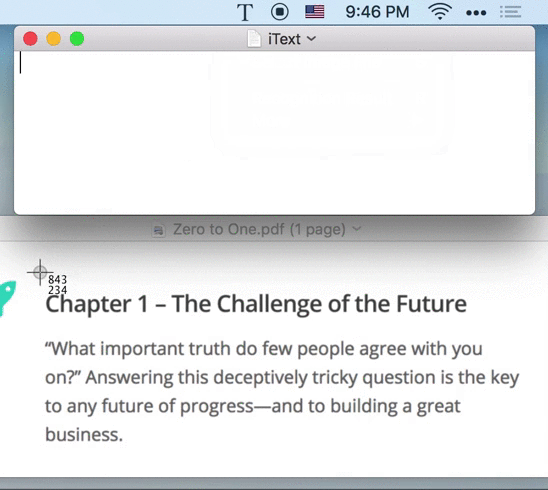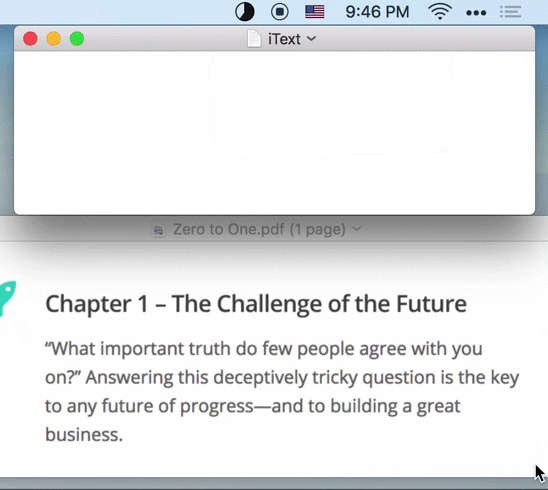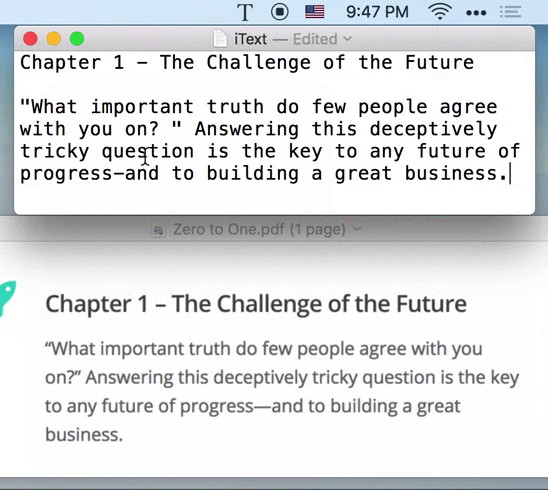
Tips: The recognized text has been copied to the system clipboard. You can paste directly.
1.2 Drag the Image to Menubar Icon
For example, when you see an image in Twitter and want to extract the text or number inside, just drag the image to iText’s menubar icon, you will get what you want.
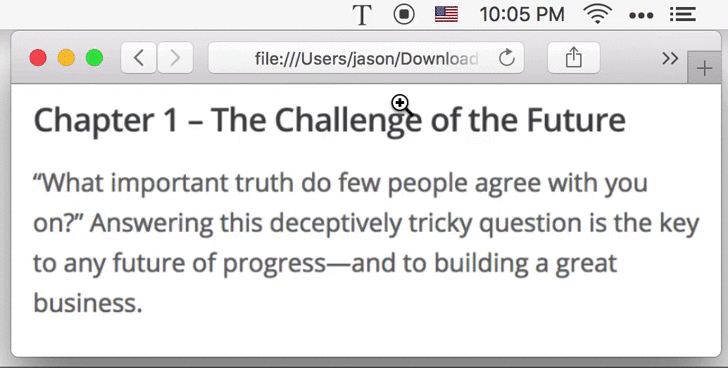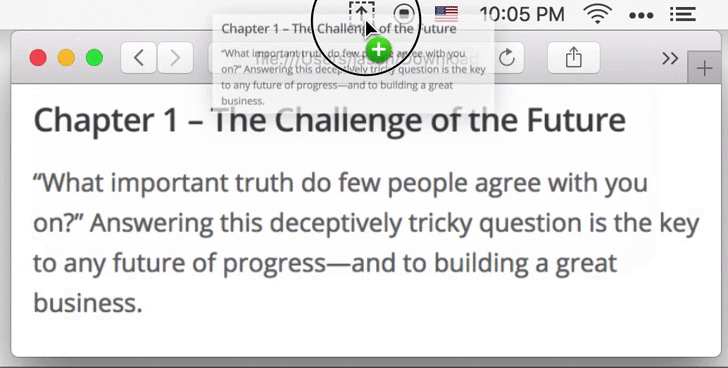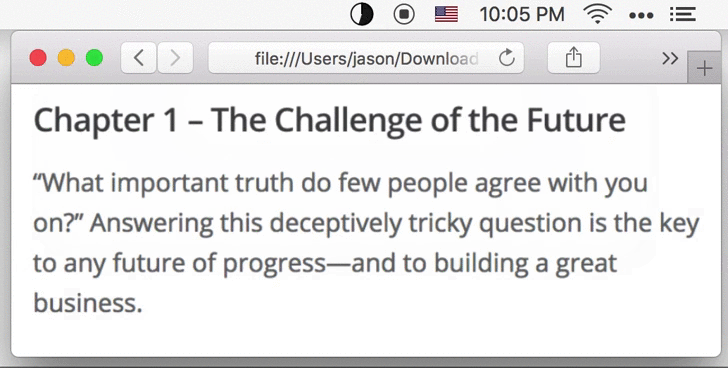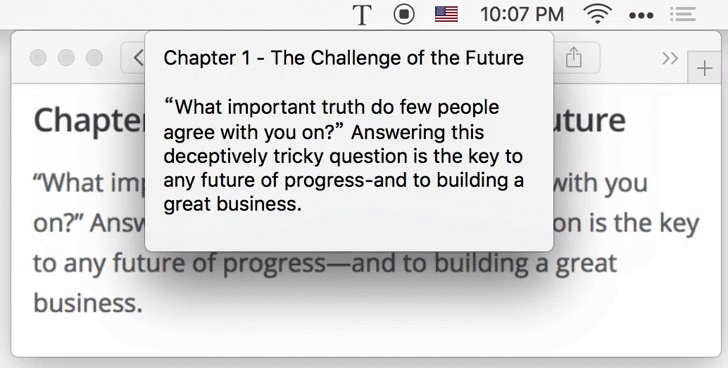
1.3 Choose Image File
Of course, you can also select a picture file to recognize. However, dragging mentioned above is preferred in this case.
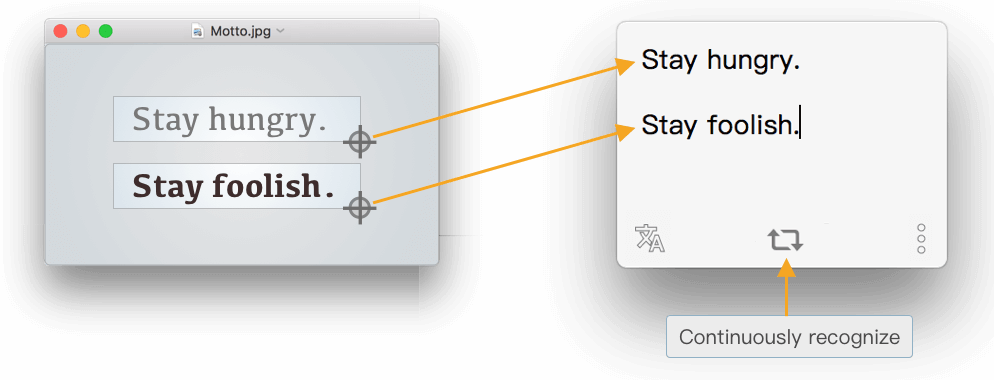
1.4 Continuously Recognize
For example, taking screenshot of different positions in PDFs, iText will recognize the text in turn and automatically concatenate the results.
2 Accurately Recognize Text
Do you have this experience: You want to extract the text from a picture and found that there are some errors in the recognized text. As a result, the time to manually modify these errors is longer than the time to type them in a computer.
Obviously, accuracy of recognition is very important, that’s why I work hard on it.
2.1 Powered by Google
First of all, I excluded offline recognition libraries, as the offline libraries are dead and can’t improve itself. Next, in many online OCR services, I compared the products of Microsoft, Google, and others.
Finally, I chose Google’s service as it’s so powerful, which could recognize 50+ languages.

- For normal natural language, such as a page of a book, press release, recognition result is amazingly accurate, even up to 100%.
- For complex typesetting, especially with special characters (e.g., program source code), the recognition result isn’t that good, You may need to manually modify the results after recognition.
- E.g,, for just a vertical line, the machine can not distinguish between the lowercase l, or uppercase I (by the way, can you identify them?); In contrast, machine needs to understand the context to optimize the result. But now it’s too hard for machine to understand non-natural language like program source code.
Welcome to have a try and feel how accurate the recognition result is.
2.2 Optimize the Recognition Results
OCR services could accurately recognize the text in image, but not that good for further recognition, e.g., paragraph recognition, etc.
So, iText includes its own algorithm to optimize the result, eg.,
- Automatically identify paragraphs.
- Remove extra spaces between English words and punctuation characters.
- Capitalize the first letter for English.
If you find that the optimization is not good, welcome to send the image to me. I will optimize the algorithm corresponding to the image. Thanks in advance.
2.3 Preview the Original Image for Proofing
As current OCR technology cannot always 100% recognize the text, it’s necessary to review the original image to modify the result. In iText, you could:
- Drag the result window nearby the image.
- Show image in left of the result window.
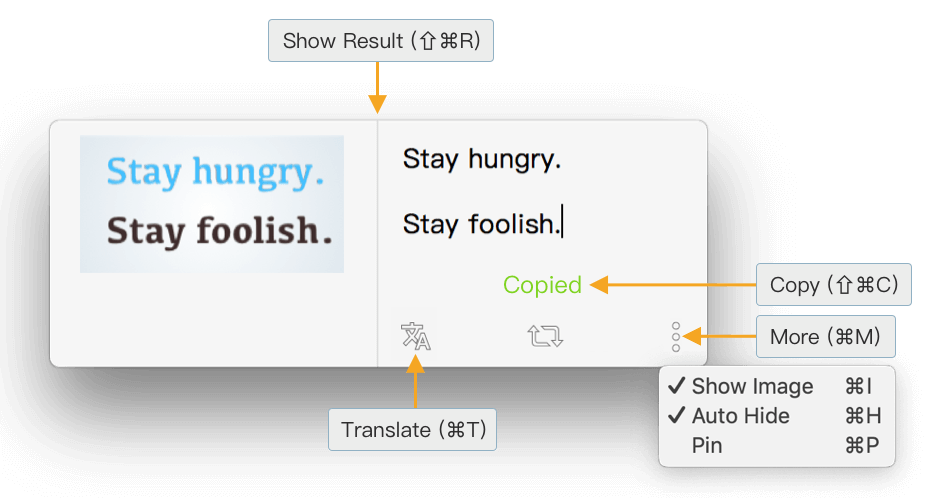
And then, you will feel easy to update the result.
2.4 Auto Hide Recognition Result
Since iText’s recognition results are very accurate and have been copied to the clipboard, there is no need to edit or copy the text after recognition. At this point, you can turn on the “Auto Hide” option as shown above, and the recognition result window will be automatically hidden after 3s, which is very convenient.
In another side, if you need to edit a recognition result temporarily, just move the mouse to the result window, and the auto hide function will be ignored this time. In addition, the window will not be automatically hidden when the “Pin” option is turned on.
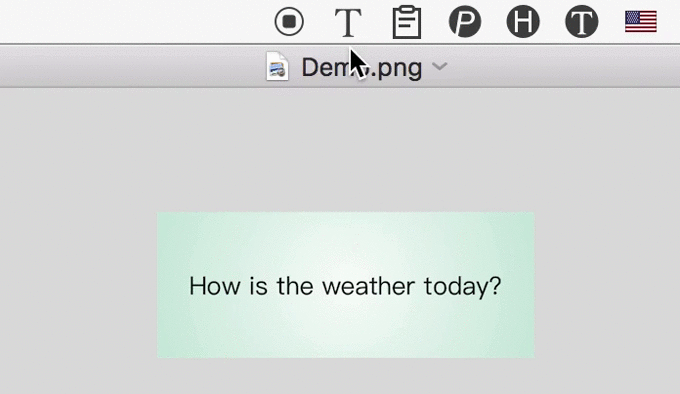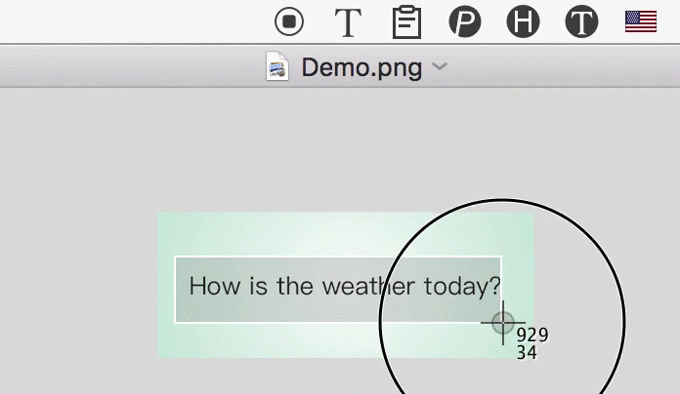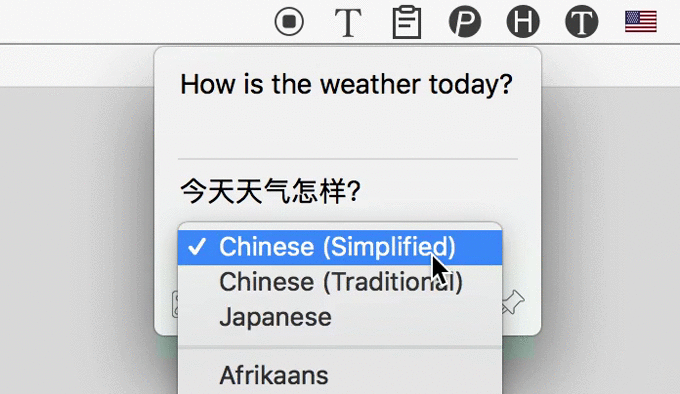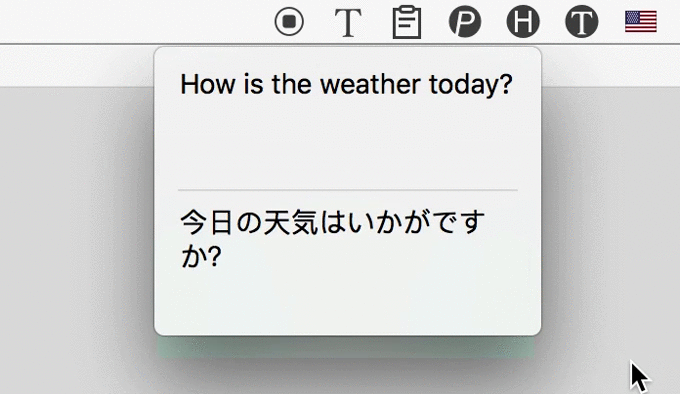
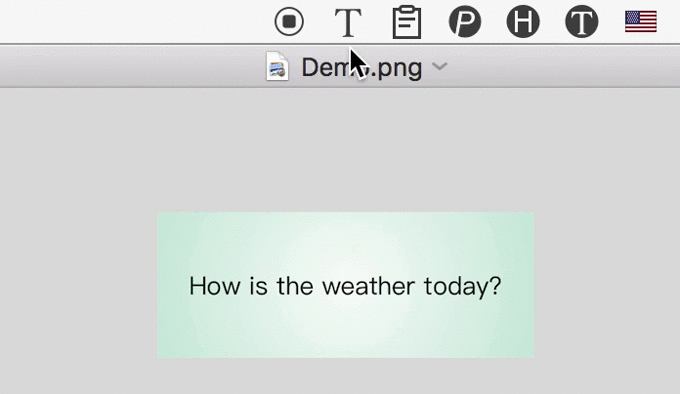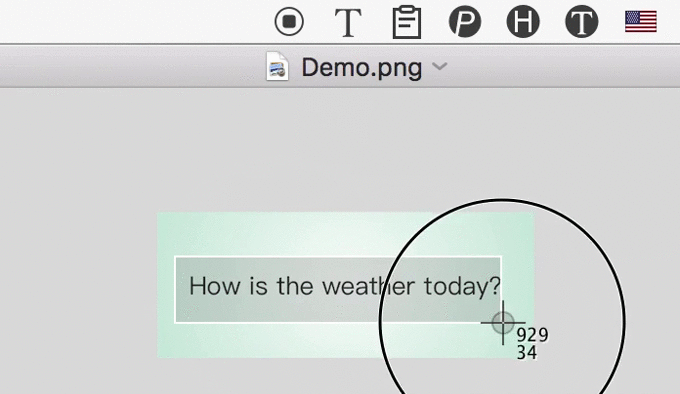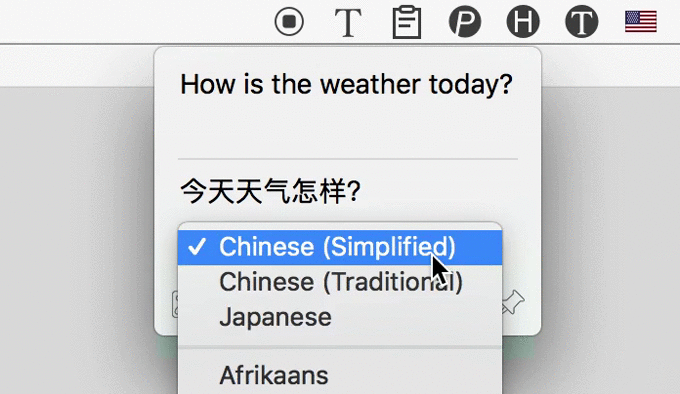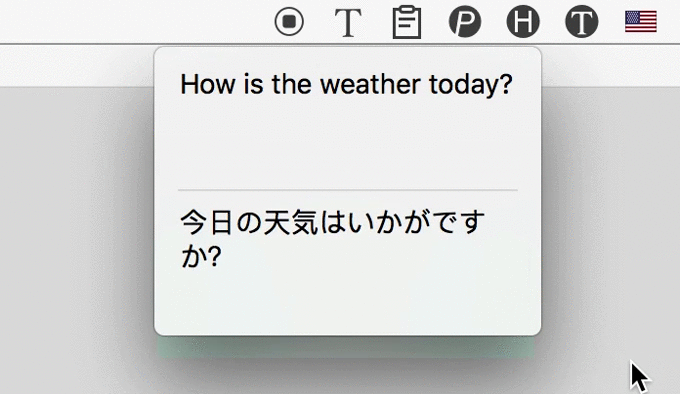
3 Automatically Translate
After recognizing text from image, iText could automatically translate them to 100+ languages, powered by Google.
Download
You can recognize text from images 20 times for free each month, or subscribe iText Pro to unlimitedly recognize text from images.
If you also feel iText is helpful, welcome to rate iText on Mac App Store and leave a small review.
If you had any problem using iText or have any suggestions for improvements, please feel free to contact me.
I’m looking forward to hearing from you.